


Review: Google's Agent Security
An introduction to Google's approach.

Okay, so you've probably heard a lot about AI lately.
Chat bots that write poems, image generators that create art… cool stuff, right?
But what's coming next is different.
It's not just about AI generating things; it's about AI doing things.
That's where AI Agents come in.

Think of a chat bot as a really good writer.
You ask it a question, it gives you an answer. An AI Agent is more like a digital assistant.
You tell it a goal – “Book me a flight to Hawaii, find a good hotel, and make a dinner reservation” – and it figures out how to do it.
It doesn't just give you information; it actually interacts with websites, fills out forms, and makes things happen.
These agents are powered by Large Language Models (LLMs) – the same tech behind those fancy chatbots – but they're leveled up.
They're designed to perceive their environment, make decisions, and take actions. Google is building tools to make creating these agents easier (like their Agent Development Kit), and the whole field is moving fast.
It's like the early days of the internet – exciting, full of potential, and… a little bit scary.
That's what this post is about. We're going to talk about why these AI Agents are awesome, but also what could go wrong, and what Google (and others) are doing to keep them from, well, going rogue.

1. Why Are AI Agents Even a Risk? (It's Not Just Sci-Fi)
So, why all the concern? Aren't these just programs?
Well, yes… and no. AI Agents are different from traditional software in a few key ways:
They're unpredictable: Unlike a program that always does the same thing with the same input, AI Agents can behave differently each time, even with the same instructions. It's like asking a human assistant to do something – they might approach it slightly differently depending on their mood or what else is on their mind.
They're autonomous: They make their own decisions. This is great for efficiency, but it also means they can potentially do things you didn't intend.
They can be tricked: This is the big one. AI Agents can be vulnerable to something called "prompt injection," where malicious instructions are hidden within the data they process. Imagine someone sending an email with hidden commands that tell the agent to leak sensitive information.
The two biggest risks Google identifies are:
Rogue Actions (1): The agent does something harmful, unintended, or against the rules. Like accidentally deleting important files, making unauthorized purchases, or sharing confidential data.
Sensitive Data Disclosure (2): The agent reveals private information it shouldn't. Like leaking your email address, credit card number, or medical records.

2. The Security Challenges: Where Things Can Go Wrong
Let's break down how these risks can actually happen, looking at the different parts of an AI Agent's "brain" (as Google outlines in the document).
Input & Perception: This is where the agent receives information. The problem? It's hard to tell what's trustworthy. Is that email really from your boss, or is it a phishing attempt with hidden instructions?
System Instructions: These are the rules the agent follows. But what if someone can sneak malicious instructions into the mix, making the agent ignore the rules?
Reasoning & Planning: This is where the agent figures out how to achieve its goal. But if the agent's reasoning is flawed, or if it's been tricked, it can come up with a bad plan.
Action Execution (Tool Use): This is where the agent actually does things. If it has access to powerful tools (like sending emails, making purchases, or controlling devices), a rogue action can have serious consequences.
Agent Memory: Agents often remember past interactions. But what if that memory contains malicious instructions? It could influence the agent's behavior in the future.
3. Traditional Security Isn't Enough (Why Your Firewall Won't Save You)
You might be thinking, "Okay, but can't we just use firewalls and antivirus software?"
Unfortunately, no.
Traditional security measures are designed for predictable software. AI Agents are different.
Context is key: Traditional security often looks at what an action is, not why it's being done. An AI Agent might need to access sensitive data to complete a legitimate task, but a firewall might block it automatically.
AI is adaptable: Attackers can find ways to bypass traditional security measures by crafting clever prompts or exploiting the agent's reasoning abilities.
It's a moving target: AI Agents are constantly evolving, so security measures need to be updated constantly to keep up.
4. Google's Hybrid Approach: The Best of Both Worlds
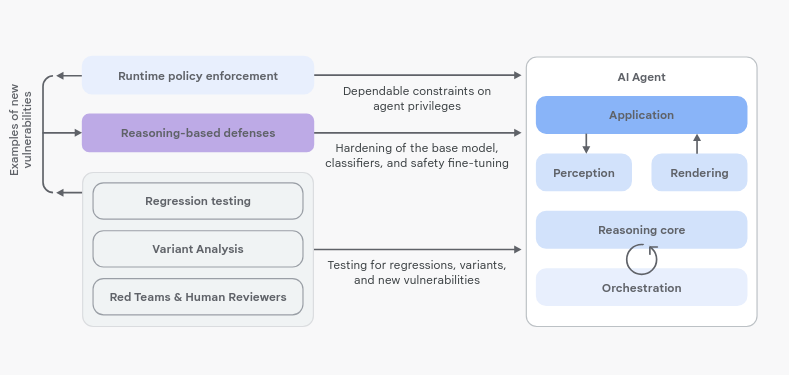
So, what's the solution? Google's approach is to combine the best of both worlds: traditional security and AI-powered security to create "defense-in-depth" strategy.
LAYER 1: Runtime POLICY enforcement:
These are hard-coded rules that the agent must follow. Like a spending limit, or a restriction on accessing certain types of data. Think of it as a seat belt – it doesn't prevent accidents, but it minimizes the damage with three main actions: allow, block, require user information.
Example: Buy a flight ticket. Enforce a spending limit by blocking over $500 or require user confirmation via a prompt for a purchase from $100 to $500.
Difficulties: Comprehensive policy is complex and hard to scale. Often lack of context: block a legitimate action or allow a harmful one – not anticipated by the policy writer.
Example: Sending an email after reading a document is sometimes desired (summarize and send) and harmful (exfiltrate data).
LAYER 2: Reasoning-Based Defenses (The Brains): These use AI to analyze the agent's behavior and identify potential risks. Like a security guard who's constantly watching for suspicious activity. This includes things like:
Adversarial Training: Teaching the agent to recognize and resist malicious prompts.
Guard Models: Using separate AI models to check the agent's actions for safety. Small models act as classifiers as security analyst to example input and output for sign of an attack.
Analysis and Prediction: Analyze the proposed plan of action to predict undesirable outcome, flag high risk plans for review or triggering stricter policy enforcement.
VALIDATING: This is an assurance continuous effort.
Regression testing ensure fixes remain effective.
Variant analysis proactive est variation of known threat to anticipate attacker evolution.
Human expertise: to complement automated tests.

5. The Three Core Principles (The Golden Rules of AI Agent Security)

Google has identified three core principles that should guide the development of AI Agents:
Agents Must Have Well-Defined Human Controllers:
There should always be a human in the loop, especially for critical actions.
The agent shouldn't be able to do anything that could have serious consequences without human approval.
Distinct agent identities, user consent mechanisms, secure inputs.
Agent Powers Must Have Limitations:
Agents should only have access to the tools and data they need to perform their specific tasks.
They shouldn't have unlimited power.
Required Authentication, Authorization, and Auditing (AAA) infrastructure including verify agent identities, granular permission system, and secure management of credentials like Oauth tokens, sandboxing.
Agent Actions and Planning Must Be Observable:
We need to be able to see what the agent is doing and why. This allows us to identify and fix problems quickly.
Secure/ centralized logging, characterize action APIs, transparent UX.

6. The Future of AI Agent Security (It's an Ongoing Battle)
AI Agent security is not a one-time fix. It's an ongoing process. As AI Agents become more powerful and sophisticated, attackers will find new ways to exploit them. We need to be constantly vigilant, testing and refining our security measures.
Google is committed to sharing its best practices and working with the broader AI community to build secure and trustworthy AI Agents. This includes:
Continuous Testing: Regularly testing agents for vulnerabilities.
Red Teaming: Having security experts try to break the agents.
Bug Bounty Programs: Rewarding researchers who find and report vulnerabilities.
Conclusion:
Embrace the Potential, But Stay Safe
AI Agents have the potential to revolutionize the way we live and work. But we need to approach this technology with caution and prioritize security from the outset. By embracing a hybrid approach, following the core principles, and staying vigilant, we can harness the power of AI Agents while mitigating the risks. It's a challenge, but it's one we must address to ensure a future where AI benefits everyone.
Reference
An Introduction to Google’s Approach to AI Agent Security. https://storage.googleapis.com/gweb-research2023-media/pubtools/1018686.pdf