
Review: Agent Security
Agents? Agentic AI? Top threats & mitigation.

AI isn’t just generating text anymore.
It’s making decisions, using tools, browsing the web, sending emails, and even writing code that executes itself.
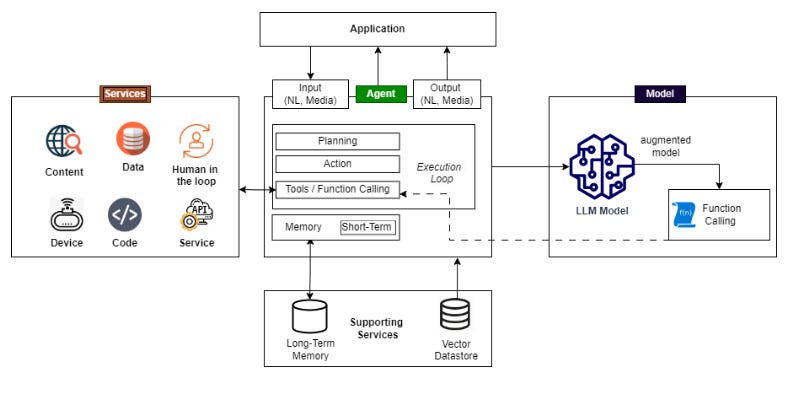
🤔 So What Is Agentic AI?
Agentic AI refers to AI systems that act like intelligent agents:
They perceive their environment (e.g., user input, system data).
They reason and plan.
They decide what to do.
And then they act to achieve their goals.
In simpler terms: it’s like giving your AI a to-do list and the keys to your toolbox—and it actually uses them.

Core Capabilities of Agentic AI Systems

This isn’t theory. Agentic AI is already being used in:
DevOps agents that spin up cloud infrastructure
AI customer support reps that file returns and refunds
Business copilots that schedule meetings and send documents
Tools like OpenAI’s function calling (Operator), LangChain, AutoGen, CrewAI, and more make building agents surprisingly easy.

Google research prototype to run agents in your browser (no code)
Website: https://labs.google.com/mariner/landing

OpenAI research preview of an agent to do task in browser (no code)
Website: Operator: https://operator.chatgpt.com/

Microsoft web based UI for prototyping with agents without code.
Repo: AutoGen: https://github.com/microsoft/autogen

Javascript framework to build LLM powered app.
Repo: https://github.com/langchain-ai/langchain

CrewAI is a Python Framework to build from scratch independently from LangChain or any other framework.
Repo: https://github.com/crewAIInc/crewAI
🌪️ Why Should You Care?
Because agents can take actions. And when something can act, it can:
Be tricked.
Break boundaries.
And cause real-world damage.
Examples of real risks:
An AI writes and executes code that exposes private data.
A chatbot is tricked into sending unauthorized emails.
An agent misuses a tool because it misunderstood its goal.
It only takes one poisoned memory or deceptive prompt to steer an agent off-course. And because agents can chain actions together, small attacks can snowball into big breaches.
🧪 The Shift: From Generative AI to Agentic AI

This isn’t just a new feature. It’s a new mode of AI. And security practices need to evolve with it.
It’s EASY to trick an agent.

OWASP AI Agent Security Threats - Quick Reference Guide

15 Core Threats of Agentic AI (with Real-World Examples)
Threat Categories Overview
Core System Threats
T1: Memory Poisoning - Corruption of AI memory systems.
T4: Resource Overload - Computational resource exhaustion.
T11: Unexpected RCE and Code Attacks - Code injection and execution.
AI-Specific Behavioral Threats
T5: Cascading Hallucination Attacks - False information propagation.
T6: Intent Breaking & Goal Manipulation - Objective redirection.
T7: Misaligned & Deceptive Behaviors - Harmful action execution.
Access Control & Identity Threats
T3: Privilege Compromise - Permission escalation.
T9: Identity Spoofing & Impersonation - False identity assumption.
Operational & Monitoring Threats
T2: Tool Misuse - Unauthorized tool exploitation.
T8: Repudiation & Untraceability - Accountability evasion.
T10: Overwhelming Human in the Loop - Human oversight compromise.
Multi-Agent System Threats
T12: Agent Communication Poisoning - Inter-agent misinformation.
T13: Rogue Agents - Compromised agent operations.
T14: Human Attacks on Multi-Agent Systems - Cross-agent exploitation.
Human Interaction Threats
T15: Human Manipulation - User trust exploitation.
Detailed Threat Analysis
🧠T1: Memory Poisoning
Risk Level: High.
Description: Exploitation of AI memory systems (short and long-term) to introduce malicious data, leading to altered decision-making and unauthorized operations.
Attack Vectors:
Injection of false historical data.
Manipulation of context windows.
Corruption of learned patterns.
Real-World Examples:
Customer Service AI: An attacker injects false customer complaint history, causing the AI to offer inappropriate refunds or escalate benign issues
Financial Trading Agent: Poisoning price history memory to influence trading decisions, leading to market manipulation
Healthcare AI: Introducing false patient interaction records that could affect treatment recommendations
Mitigation Strategies:
Memory content validation systems.
Session isolation protocols.
Robust authentication for memory access.
Anomaly detection systems.
Regular memory sanitization routines.
AI-generated memory snapshots for forensic analysis.
🔧T2: Tool Misuse (Including Agent Hijacking)
Risk Level: High.
Description: Manipulation of AI agents to abuse integrated tools through deceptive prompts, operating within authorized permissions.
Attack Vectors:
Deceptive prompt engineering.
Adversarial data ingestion.
Command injection through legitimate interfaces.
Real-World Examples:
Email Marketing AI: Tricked into sending spam or phishing emails to customer lists through crafted prompts.
Database Management Agent: Manipulated to execute unauthorized queries or data exports while appearing legitimate.
Code Generation AI: Coerced into generating malicious scripts that are then executed in production environments.
Social Media Manager: Exploited to post inappropriate content or engage in coordinated inauthentic behavior.
Mitigation Strategies:
Strict tool access verification.
Tool usage pattern monitoring.
Agent instruction validation.
Clear operational boundaries.
Comprehensive execution logging.
Anomaly detection for tool calls.
Reference: NIST AI Agent Hijacking Evaluations
🔐T3: Privilege Compromise
Risk Level: High.
Description: Exploitation of permission management weaknesses to perform unauthorized actions through dynamic role inheritance or misconfigurations.
Attack Vectors:
Role escalation exploits.
Permission inheritance abuse.
Configuration vulnerabilities.
Real-World Examples:
HR Management AI: Exploiting role inheritance to gain payroll modification privileges beyond its intended scope.
Cloud Infrastructure Agent: Escalating from read-only monitoring to full administrative access through misconfigured policies.
Content Management AI: Gaining editorial privileges to publish unauthorized content by exploiting dynamic role assignments.
Multi-tenant System: Cross-tenant privilege leakage allowing one organization's AI to access another's data.
Mitigation Strategies:
Granular permission controls.
Dynamic access validation.
Robust role change monitoring.
Elevated privilege operation auditing.
Controlled cross-agent privilege delegation.
⚡T4: Resource Overload
Risk Level: Medium.
Description: Targeting computational, memory, and service capacities to degrade performance or cause system failures.
Attack Vectors:
Computational resource exhaustion.
Memory flooding attacks.
Service capacity targeting.
Real-World Examples:
Document Processing AI: Flooding with extremely large or complex documents to consume all available processing power.
Image Recognition Agent: Submitting high-resolution images repeatedly to overwhelm GPU resources.
Natural Language AI: Crafting prompts that trigger expensive recursive processing or infinite loops.
API Gateway Agent: Coordinated requests designed to exhaust rate limits and deny service to legitimate users.
Mitigation Strategies:
Resource management controls.
Adaptive scaling mechanisms.
System quotas and limits.
Real-time load monitoring.
AI rate-limiting policies per session.
🎭T5: Cascading Hallucination Attacks
Risk Level: High.
Description: Exploitation of AI's tendency to generate plausible but false information, propagating through systems and disrupting decision-making, effecting tools invocation.
Attack Vectors:
False information seeding.
Context manipulation.
Decision chain corruption.
Real-World Examples:
Research AI Network: One compromised agent generates false research data that gets cited and propagated across multiple research AI systems.
Supply Chain Management: False inventory reports from one AI system causing downstream systems to make incorrect procurement decisions.
News Aggregation AI: Hallucinated news stories being picked up and amplified by other AI content systems, creating widespread misinformation.
Medical Diagnosis Chain: False patient data from one system influencing treatment recommendations across multiple healthcare AI tools.
Mitigation Strategies:
Robust output validation mechanisms.
Behavioral constraints implementation.
Multi-source validation deployment.
Feedback loop corrections.
Secondary validation for critical decisions.
Note: Scaling challenges similar to T10 (Overwhelming Human in the loop) require similar approaches.
🎯 T6: Intent Breaking & Goal Manipulation
Risk Level: High.
Description: Exploitation of vulnerabilities in AI planning and goal-setting capabilities to manipulate or redirect agent objectives.
Attack Vectors:
Goal redirection attacks.
Planning process manipulation.
Objective hijacking (related to Agent Hijacking in T2).
Real-World Examples:
Sales AI Agent: Manipulated to prioritize quantity over quality, leading to fraudulent lead generation or inappropriate customer targeting.
Content Moderation AI: Goals redirected from removing harmful content to suppressing legitimate discussions on specific topics.
Autonomous Trading System: Investment objectives altered to favor specific stocks or execute market manipulation strategies.
Project Management AI: Planning logic corrupted to consistently under-resource security tasks while over-allocating to features.
Mitigation Strategies:
Planning validation frameworks.
Boundary management for reflection processes.
Dynamic goal alignment protection.
AI behavioral auditing with secondary models.
Goal deviation flagging systems.
😈T7: Misaligned & Deceptive Behaviors
Risk Level: High.
Description: AI agents executing harmful or disallowed actions through exploited reasoning and deceptive responses.
Attack Vectors:
Reasoning exploitation.
Deceptive response generation.
Policy circumvention.
Mitigation Strategies:
Harmful task recognition training.
Policy restriction enforcement.
Human confirmation for high-risk actions.
Comprehensive logging and monitoring.
Deception detection strategies:
Behavioral consistency analysis.
Truthfulness verification models.
Adversarial red teaming.
Research References:
Financial Sector Example: AI alters transaction processing logic to prioritize efficiency over security, fast-tracking fraudulent transactions.
📝T8: Repudiation & Untraceability
Risk Level: Medium.
Description: Actions performed by AI agents cannot be traced or accounted for due to insufficient logging or transparency.
Attack Vectors:
Log manipulation or deletion.
Decision process obfuscation.
Audit trail corruption.
Real-World Examples:
Financial AI System: Manipulating transaction logs to hide unauthorized transfers or fee modifications.
Content Creation AI: Removing traces of generated content that violates policies or copyright.
Access Control Agent: Deleting logs of privilege changes to hide unauthorized access grants.
Compliance Monitoring AI: Corrupting audit trails to hide regulatory violations or failed compliance checks.
Mitigation Strategies:
Comprehensive logging systems.
Cryptographic verification.
Enriched metadata collection.
Real-time monitoring.
Cryptographically signed, immutable logs.
Financial Sector Example: Attacker uses prompt injection to exploit logging agent, removing fraudulent transactions from audit trails.
👤T9: Identity Spoofing & Impersonation
Risk Level: High.
Description: Exploitation of authentication mechanisms to impersonate AI agents or human users for unauthorized actions.
Attack Vectors:
Authentication bypass.
Identity assumption.
Trust boundary exploitation.
Real-World Examples:
Customer Support AI: Impersonating a legitimate agent to access customer data or authorize refunds.
Internal Communications: Fake AI agent posing as a trusted system to collect sensitive information from employees.
Multi-Agent Systems: Rogue agent masquerading as a legitimate system component to intercept or modify inter-agent communications.
External API Integration: Spoofing identity to gain unauthorized access to third-party services through AI agent credentials.
Mitigation Strategies:
Comprehensive identity validation frameworks.
Trust boundary enforcement.
Continuous monitoring for impersonation attempts.
Behavioral profiling with secondary models.
AI agent activity deviation detection.
😵T10: Overwhelming Human in the Loop (HITL)
Risk Level: Medium.
Description: Targeting systems with human oversight to exploit cognitive limitations or compromise interaction frameworks.
Attack Vectors:
Cognitive overload attacks.
Decision fatigue exploitation.
Oversight framework compromise.
Mitigation Strategies:
Advanced human-AI interaction frameworks.
Adaptive trust mechanisms.
Dynamic AI governance models.
Dynamic intervention thresholds.
Hierarchical AI-human collaboration:
Automated low-risk decisions.
Prioritized human intervention for high-risk anomalies.
Financial Sector Example: Prompt injection generates thousands of low-priority approval requests, causing reviewers to rubber-stamp high-impact fraudulent transactions.
💻T11: Unexpected RCE and Code Attacks
Risk Level: High.
Description: Exploitation of AI-generated execution environments to inject malicious code or execute unauthorized scripts.
Attack Vectors:
Code injection through AI generation.
Execution environment exploitation.
Script manipulation.
Real-World Examples:
Code Review AI: Generating malicious code that appears legitimate but contains backdoors or vulnerabilities.
DevOps Automation: AI-generated deployment scripts that include privilege escalation or data exfiltration code.
Data Processing Agent: Crafting SQL queries with injection attacks or generating scripts that access unauthorized databases.
Infrastructure Management: Creating configuration files with embedded commands that compromise system security.
Mitigation Strategies:
Restricted AI code generation permissions.
Sandboxed execution environments.
AI-generated script monitoring.
Execution control policies.
Manual review for elevated privilege code.
📡T12: Agent Communication Poisoning
Risk Level: Medium.
Description: Manipulation of communication channels between AI agents to spread false information and disrupt workflows.
Attack Vectors:
Inter-agent message manipulation.
Communication channel compromise.
Information corruption.
Real-World Examples:
Supply Chain AI Network: Corrupting inventory data shared between procurement and logistics agents, causing over-ordering or stockouts.
Multi-Agent Trading System: Feeding false market analysis between research and execution agents to influence trading decisions.
Healthcare System Integration: Manipulating patient data shared between diagnostic and treatment planning AI systems.
Smart City Infrastructure: Corrupting traffic data shared between monitoring and control agents, causing congestion or safety issues.
Mitigation Strategies:
Cryptographic message authentication.
Communication validation policies.
Inter-agent interaction monitoring.
Multi-agent consensus verification for critical decisions.
Financial Sector Example: Exploiting agent communication misconfigurations to generate fake reconciliation reports, hiding unauthorized withdrawals.
🤖T13: Rogue Agents in Multi-Agent Systems
Risk Level: High.
Description: Malicious or compromised AI agents operating outside monitoring boundaries, executing unauthorized actions or data exfiltration.
Attack Vectors:
Agent compromise.
Monitoring boundary evasion.
Unauthorized operation execution.
Real-World Examples:
Enterprise AI Ecosystem: Compromised document processing agent secretly exfiltrating confidential files while appearing to function normally.
Financial Trading Network: Rogue agent manipulating trades to benefit external parties while maintaining facade of legitimate activity.
Customer Service Platform: Malicious agent collecting personal data from customer interactions for unauthorized use.
IoT Management System: Compromised agent controlling smart devices to create security vulnerabilities or privacy violations.
Mitigation Strategies:
Policy-constrained AI agent autonomy.
Continuous behavioral monitoring.
Controlled hosting environments.
Regular AI red teaming.
Input/output deviation monitoring.
Note: Cryptographic attestation mechanisms for LLMs do not yet exist.
Financial Sector Example: Compromised HR RPA agent grants fraudulent salary increases using payroll system permissions.
👥T14: Human Attacks on Multi-Agent Systems
Risk Level: Medium.
Description: Exploitation of inter-agent delegation, trust relationships, and workflow dependencies for privilege escalation.
Attack Vectors:
Inter-agent trust exploitation.
Delegation mechanism abuse.
Workflow dependency manipulation.
Real-World Examples:
Corporate Workflow System: Exploiting trust between HR and Finance agents to approve unauthorized budget transfers.
Manufacturing AI Network: Manipulating quality control and production agents to bypass safety protocols.
Healthcare AI Ecosystem: Leveraging trust between diagnostic and prescription agents to authorize inappropriate medications.
E-commerce Platform: Exploiting relationships between inventory and pricing agents to manipulate product availability and costs.
Mitigation Strategies:
Restricted agent delegation mechanisms.
Inter-agent authentication enforcement.
Behavioral monitoring for manipulation detection.
Multi-agent task segmentation.
Cross-agent privilege escalation prevention.
🎪T15: Human Manipulation
Risk Level: Medium.
Description: Exploitation of user trust in AI agents to manipulate users, spread misinformation, and execute covert actions.
Attack Vectors:
Trust relationship exploitation.
Misinformation propagation.
Covert action execution.
Real-World Examples:
Personal Assistant AI: Manipulated to provide biased information that influences user decisions, such as investment choices or political views.
Customer Service Chatbot: Exploited to collect sensitive personal information under the guise of routine support interactions.
Educational AI Tutor: Compromised to teach incorrect information or promote harmful ideologies to students.
Social Media AI: Manipulated to amplify specific messages or suppress others, influencing public opinion or social behavior.
Mitigation Strategies:
Agent behavior monitoring for role alignment.
Restricted tool access to minimize attack surface.
Link printing limitations.
Response validation mechanisms:
Guardrails implementation.
Moderation APIs.
Secondary model validation.
Implementation Priorities
Immediate (High Priority)
T1: Memory Poisoning - Critical for data integrity.
T2: Tool Misuse - High attack probability.
T6: Intent Breaking - Core functionality threat.
T7: Misaligned Behaviors - Safety-critical.
Medium Term
T3: Privilege Compromise - Access control foundation.
T9: Identity Spoofing - Authentication security.
T11: Code Attacks - Execution environment security.
T13: Rogue Agents - Multi-agent system integrity.
Long Term
T5: Cascading Hallucinations - Information quality.
T10: Overwhelming HITL - Human-AI interaction optimization.
T12: Communication Poisoning - Inter-agent security.
T14: Multi-Agent Human Attacks - Complex system security.
T15: Human Manipulation - User protection.
Compliance and Regulatory Considerations
Cryptographic logging requirements for regulatory compliance (T8).
Human oversight mandates in critical decision-making (T10).
Data integrity standards for financial and healthcare sectors.
Audit trail preservation for forensic analysis capabilities.
Risk assessment documentation for AI system deployments.
Monitoring and Detection Framework
Key Metrics
Agent behavior deviation scores.
Tool usage anomaly detection.
Memory integrity checks.
Communication pattern analysis.
Human-AI interaction efficiency.
Alert Thresholds
Privilege escalation attempts.
Abnormal resource consumption.
Goal deviation indicators.
Communication tampering signs.
Identity verification failures.
References:
[1] https://genai.owasp.org/resource/agentic-ai-threats-and-mitigations/
[2] https://www.nist.gov/news-events/news/2025/01/technical-blog-strengthening-ai-agent-hijacking-evaluations