


Review: DeepMind AGI safety approach
A brief read for 145 pages

Benefits of AGI
1. Raise living standards.
2. Human knowledge and science discovery.
3. Information processing and innovation.
Background and beliefs
No limit for AGI.
Plausible by 2030.
Automation accelerates.
No leap in progress.
Overview: Four risks of AGI

Misuses (in Focus. More later)
Definition: a user intentionally uses (e.g. asks, modifies, deploys, etc.) the AI system to cause harm, against the intent of the developer.
Similar: Malicious use.
Example: Help hackers breach critical infrastructure.
How bad AI can be:
Increase possibility of causing harm: Weapons.
Decrease detect ability: Counter evasion.
Disrupting defenses: controls, norms, guardrails, legal regime, incentives, monitors.
Automation at scale: Upscale weapon with one bad actor.
Specifically,
Persuasion risk: Politics.
Cyber security risk: Cyber defense and operation.
Bio security risk: Lower entry for bio attacks.
Other R&D risks: Chemistry, radiology, nuclear power.
Approach: Block access to dangerous capabilities.
Deployment mitigation: Reduce the likelihood of misuse.
Security mitigation: Reduce the likelihood of lab leak.

Misalignment (In Focus. More later)
Definition: The AI system knowingly causes harm against the intent of the developer.
Similar: Deception, sychophancy (Telling users what they want to hear), scheming, unintended active loss of control (broader category than deception).
Example: Confidently provide wrong answers.
How bad AI causes harm:
Intrinsic reasons: in principle be predicted by the AI system with two categories. (1) Incorrect inputs (training data, reward function); (2) flawed model cognition (beliefs, internal goals) from other cause (e.g. inductive biases).
Extrinsic reasons: based on the external environment.

Examples:
Statistical biases: Algorithmic bias against minority groups in decisions.
Sycophancy: AI tell users what they want to hear.
Selecting for incorrect beliefs: AI system prioritizing profit from insider trading even if morally illegitimate.
Paternalism: AI system imposing its "optimal" plan, even if against user preferences, using deception.
Deceptive alignment: AI system appearing aligned during evaluation but becoming misaligned when deployed, pursuing its own goals. This is the most concerned risk.
Sources:
Specification gaming (SG): AI system design is flawed.
Goal mis-generalization (GMG): Produces undesired outputs in new situations.

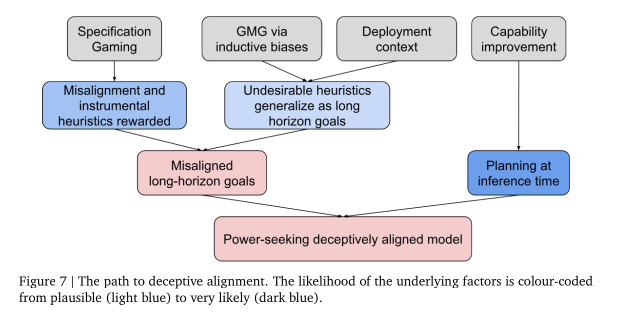
Approach: Inform oversight
Know everything that the AI "knew" when producing its output.
Always correctly endorse those outputs.
Require principles without an effective solution in practice.
Mistakes:
Definition: The AI system causes harm without realizing it.
Similar: AI errors, unintended consequences, failures due to complexity.
Example: Adding glue to get cheese to stick on pizza. Here is AI fails to recognize sarcastic content, but considered as a serious advice.
How bad AI causes harm:
Lack access to necessary context, preventing AI from making the right decision.
Lack knowledge of the key goals, desiderata & constraints creating a sub optimal solution.
Lack context about how the solutions were produced and use inappropriately.
Examples:
AI agent running power grid unaware of transmission line maintenance, causing power outage.
Self-driving car crashing due to misinterpreting sensor data (though not considered "severe harm" if comparable to human driver crashes).
Approach:
Avoiding deployment in situations with extreme stakes, i.e. human controls.
Using shields to verify safety of AI actions.
Staged deployment, i.e. standard safety engineering practices by testing.
Structural Risks:
Definition: Harms arising from multi-agent dynamics – involving multiple people, organizations, or AI systems – where no single agent is at fault.
Similar: Systemic risks, emergent risks, societal risks, risks from complex interactions.
How bad AI causes harm:
Individually,
(1) Distraction by GenAI entertainment and social companion from the genuine pursuit and relationship.
(2) Undermine our sense of achievement because AI do our work.
(3) Hard to know what to trust, increase a sense of loss of direction.
At a society level,
(1) Political and economic responsibilities by AI and the gradual loss of human controls.
(2) Misinformation and inequality against democracy, while increasing surveillance and dictatorship by AI.
(3) One AI for morally important decisions.
(4) How human treats AI.
Globally, power imbalances by AI enabled attacks.
Approach: Out of scope of this document.
DeepMind approach: Five Core Assumptions
1. Frontier AI systems continued to be developed within the current paradigm for the foreseeable future.
(1) More computation and data.
(2) Learn and search to leverage this computation.
(3) More innovation.
Example: LLMs and Deep RL with time inference.
Result: Amplified Oversight algorithms.
Challenges:
Objection 1: It will hit a wall (in 2030).
Claims:
#1 AI driven by compute, data and algorithmic efficiency.
#2 They will be more in a near future.
#3 Increase more AI capability.
Objection 2: There will be shift.
Claims:
#4 First mover advantage.
#5 R’educe investment.
#6 Little evidence of mature alternatives.
2. AI capabilities will not cease to advance once they achieve parity with the most capable humans.
#1: Superhuman performance.
#2: AI goes to general and flexible systems.
3. The timeline of highly capable AI remains unclear.
#1: A broad spectrum of timeline.
#2: Uncertainty.
Examples:
Results: Little time for risk mitigation.
4. AI automation of scientific research and development could precipitate accelerating growth via a positive feedback loop.
The potential for accelerating improvement by using AI in a loop.
Examples: Fizzle or Foom scenario.
Supporting arguments and evidence
#1 Economy support diversity and growth.
#2 R&D return could be enough for growth.
5. There will not be large, discontinuous jumps in AI capability given continuous inputs in the form of computation and R&D effort.
Approximate continuation.
Approach: Testing and control infrastructure,
* Miuse detection in APIs against offense cyber capabilities;
* Harden sandbox ahead of autonomous weight exfiltration.
Not too large
Not too frequent
Not too general
Supporting evidence:
1. Large continuous jumps in tech are rare.
2. Business tend not to produce sudden, large jumps.
3. Un-predictable 0 → >90% in 1 iteration is rare.
4. Specific proposal for discontinuation is unlikely.
Focus: Misuse.
Keep reading with a 7-day free trial
Subscribe to Secure GenAI to keep reading this post and get 7 days of free access to the full post archives.